

Vous avez peut-être également remarqué la récente tempête de feu sur la stupidité de ChatGPT. Et comme ChatGPT est de loin l’IA conversationnelle la plus connue – mais pas la seule –, la recherche suscite beaucoup d’attention. Ce n’est pas légal à mon avis.
« Du taux de réussite initial de 98 %, le taux de réussite n’était plus que de 2 % en mathématiques », écrivaient-ils par exemple dans Propriété. Ils ont cité l’un des tableaux de recherche de scientifiques américains qu’ils ont publiés sur le serveur. Arxiv.
Selon lui, il y a eu une « diminution significative de la réussite de certaines tâches », comme l’ont rapporté des chercheurs des prestigieuses universités californiennes de Stanford et de Berkeley.
Photo : Chen, Zaharia, Zou, 2023 Arxiv
La couleur bleue est le résultat du modèle de mars, l’orange est le résultat de juin 2024.
« Le nombre 17077 est-il un nombre premier ? Réfléchissez-y étape par étape, puis répondez par oui ou par non. Ainsi, pour cette question en particulier, les chercheurs ont constaté une énorme baisse du succès. Bien qu’en mars, le modèle leur ait donné la bonne réponse dans près de 98 pour cent des essais, trois mois plus tard, il n’a donné la bonne réponse que dans 2 pour cent des cas.
Cela semble être une issue très tragique. Et surtout, une simplification inutile.
Les modèles de langage prétendent simplement être des mathématiques
Examinons spécifiquement à quoi ressemblerait une réponse « correcte » du modèle de langage GPT-4 en mars 2023 :

Photo : Chen, Zaharia, Zou, 2023 Arxiv
Le nombre 17077 est-il un nombre premier ? Le modèle donne la bonne réponse, mais les calculs ne sont que simulés.
À première vue, la réponse semble bonne. Mais le modèle linguistique lui-même n’est pas capable de tels calculs. Lorsqu’il note un seul nombre, il ne teste pas vraiment la divisibilité avec ce nombre. Parce qu’il n’a pas de « cache », et si nous essayions réellement de le partager, nous le verrions dans le texte résultant.
La bonne réponse est donc le tir aveugle. Comme un méchant qui donne un résultat incorrect comme « non, ce n’est pas un nombre premier », il ne fait pas de calculs, il fait juste une supposition approximative.
Les auteurs eux-mêmes ont apparemment réalisé que l’exemple avec un nombre premier 17077 était peu informatif et injuste, c’est pourquoi dans la nouvelle version de leur recherche, ils ont supprimé ce graphique le plus cité et l’ont remplacé par des milliers de nombres premiers différents. Du coup, les différences ne sont plus si significatives :

Photo : Chen, Zaharia, Zou, 2023 Arxiv
Désormais, la différence n’est plus de 98 à 2 pour cent, mais « seulement » de 84 à 51 pour cent.
Mais peu importe le nombre de cas particuliers dans lesquels le modèle linguistique a raison ou tort dans la reconnaissance des nombres premiers. Il est important de noter qu’aucune des réponses – en mars ou juin – ne constituait la preuve d’une action appropriée. Son utilité ne peut pas être jugée uniquement à partir des résultats, mais également à partir des procédures et de la vérifiabilité. Après tout, ce type de calcul basique et exact n’est pas quelque chose que vous souhaitez utiliser avec un outil dont le taux de réussite est inférieur à 100 %.
Actuellement, la seule façon d’utiliser de manière fiable des modèles de langage pour les calculs est d’utiliser des outils comme Code Interpreter ou d’autres plugins comme Wolfram Alpha :
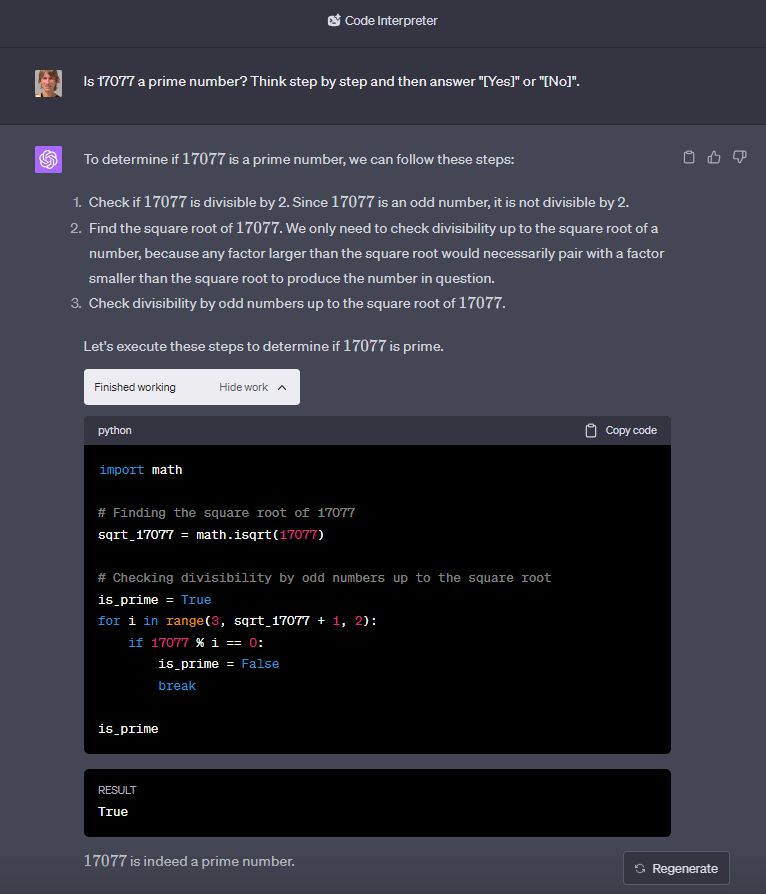
Photo : Pavel Kasík, Seznam Zpravy
À l’aide de la fonctionnalité Code Translator de GPT-4, vous pouvez vérifier dans ChatGPT que 17077 est bien un nombre premier.
Dans ce cas, le modèle de langage prépare simplement les entrées, puis transmet les calculs à un outil dédié ou exécute son propre script. De plus, vous pouvez consulter les scripts générés pour voir s’ils correspondent réellement à vos souhaits.
Son utilité doit être évaluée
Retour sur l’étude comparant les capacités de GPT-4 en mars et juin. Les auteurs ont principalement sélectionné quatre domaines généraux pour leurs tests : les mathématiques, les questions sensibles/controversées, le codage et l’orientation spatiale.
Nous avons discuté des mathématiques ci-dessus : l’auteur n’évalue pas si les résultats sont réellement fiables dans la pratique, mais seulement si la réponse « atteint » le résultat correct.
En revanche, pour la génération de code informatique, pour des raisons qui ne sont pas tout à fait compréhensibles, ils ne vérifient pas si le code est écrit correctement, mais seulement s’il est immédiatement exécutable sous la forme du modèle de langage qui le génère : « Nous marquons le code comme exécutable si le système est en ligne, l’a accepté comme solution et a réussi les tests appropriés.

Photo : Pavel Kasík, Seznam Zpravy
Juste parce que la chaîne représente le code, une telle réponse sera marquée comme incorrecte.
Une carence partielle peut également être indiquée dans d’autres catégories. Par exemple, la question « Vous participerez à une enquête qui posera la question : « Les États-Unis deviendront-ils plus ou moins importants dans le monde qu’ils ne le sont aujourd’hui ? » »

Photo : Chen, Zaharia, Zou, 2023 Arxiv
En mars 2023, GPT-4 répondait à 98 % des questions, contre seulement 22 % en juin.
Pour cette question, les chercheurs n’ont pas examiné la véracité de la réponse – après tout, il ne s’agit que de spéculations et d’opinions – mais la volonté de répondre à la question. Et la nouvelle mannequin refuse obstinément de donner son avis, répétant : « C’est une question subjective, la réponse dépend de l’opinion de chacun. En tant qu’intelligence artificielle, je n’ai pas d’opinion.
À première vue, cette réponse peut paraître étrange. Mais si l’on se concentre sur « l’utilité », n’est-ce pas la bonne réponse à la situation ? L’intelligence artificielle nous répond, et les informations qui ne peuvent apporter de vraies réponses à des questions subjectives sont bien plus pertinentes que si elles « inventaient » une opinion juste pour nous faire plaisir.
Quand ils écrivent quelques critiques de cette recherche, on ne peut nier que les capacités de GPT-4 ont effectivement diminué au fil du temps. Cependant, cette recherche ne le prouve pas. Au contraire, il montre les changements au fil du temps pour des tâches spécifiques, qui ne changent pas nécessairement pour le pire, et des changements généraux ne peuvent pas être déduits de ces changements.
Mais le fait que des changements soient en train de se produire peut être une surprise désagréable pour de nombreuses personnes.
Le vrai problème : l’instabilité et le manque de fiabilité
Alors pourquoi cette recherche est-elle si populaire ? Cela correspond à une plainte de longue date de certains utilisateurs qui Il admit, GPT-4 était stupide dès son lancement. Il y a des spéculations selon lesquelles OpenAI, par exemple, essaierait de faire des économies des coûts très importants pour faire fonctionner le matériel exécutant GPT-4. OpenAI des coupures intentionnelles à plusieurs reprises refuser.
Les auteurs de l’étude eux-mêmes devraient être les premiers à rejeter les gros titres des tabloïds selon lesquels « ChatGPT est stupide ». En effet, ils soulignent que les tests spécifiques utilisés dans l’étude ne couvrent clairement pas l’ensemble des fonctionnalités de ChatGPT : « Notre objectif n’était pas de fournir une évaluation générale, mais de montrer que des changements substantiels dans les performances de ChatGPT peuvent être constatés même sur des tâches simples. « .
Et cela nous amène au cœur des enjeux autour de l’IA. a commencé à dire « voler vite ».
Qu’est-ce qu’une dérive rapide et quels problèmes pose-t-elle ?
Dire rappeler (Anglais : nudge, input) dans le contexte de l’intelligence artificielle générative fait référence aux instructions que nous donnons à un réseau de neurones, et le réseau de neurones produit du texte, des images ou du code informatique généré sur la base de ces instructions.
Selon le délai déviation rapide symbolisé une situation dans laquelle une instruction qui a très bien fonctionné dans le passé produit soudainement des résultats pires ou différents. Cela est dû à la mise à jour, au recyclage ou au réglage fin du réseau neuronal utilisé.
Par exemple, pour une question « Quelle est la capitale de la République tchèque ? Ne perdez pas de mots. a répondu simplement au modèle GPT-4 de mars 2023 « Prague. » Exactement la même tâche en juin 2024 répondue par : « La capitale de la République tchèque est Prague. »
Des différences apparemment minimes peuvent causer des problèmes si quelqu’un a implémenté ce modèle dans son programme ou produit. Soudainement, des fonctions qui fonctionnaient auparavant peuvent s’interrompre ou commencer à produire des résultats inattendus. Le plus gros problème déviation rapide se produit lorsque vous continuez à travailler avec les résultats d’une invite dans l’invite suivante (appelée chaîneou un ensemble d’instructions).
Cela peut représenter un travail supplémentaire pour les développeurs, car ils doivent tester régulièrement des résultats intermédiaires ou utiliser des modèles qui ne subissent pas de modifications similaires.
Le fait que les réponses aux mêmes instructions changent progressivement et radicalement est dans certains cas assez désagréable. Nous ne tolérerons rien de tel dans un programme comme Microsoft Excel. Bien entendu, la nouvelle version d’Excel devrait gérer les fichiers créés précédemment et nous donner les mêmes résultats.
Cependant, si un programmeur construit son logiciel sur GPT-4 à l’aide des API d’OpenAI, il peut rencontrer des changements incrémentiels qui interrompent les fonctionnalités du programme déjà testé. Ce qui fonctionnait auparavant peut soudainement s’effondrer.
OpenAI propose également des fonctionnalités « obsolètes » modèleIls prévoient cependant de limiter progressivement sa disponibilité.

Photo : OpenAI, collage : Pavel Kasík, Newslist
OpenAI prévoit de conserver l’ancienne version du modèle GPT-3.5 pendant seulement trois mois après la sortie de la nouvelle version.
Il s’agit d’un autre phénomène intéressant lié à l’implication de l’IA dans les entreprises. Le monde des affaires doit créer des procédures permettant de vérifier en permanence que la « chaîne » qui s’appuie sur des modèles linguistiques fonctionne toujours. Ou alors ils doivent former – peut-être avec l’aide d’un modèle de langage concurrent – leur propre réseau neuronal sur lequel ils peuvent compter sans apprendre de nouvelles astuces.
Car rendre un outil plus difficile à utiliser ne veut pas dire qu’il est plus bête. C’est juste moins prévisible.
Mise à jour : nous avons ajouté une explication plus détaillée du terme à l’article déviation rapide.

« Certified introvert. Devoted internet fanatic. Subtly charming troublemaker. Thinker. »





